uriparser 0.9.6 with security fixes released
Earlier today uriparser 0.9.6 has been released. Version 0.9.6 comes with security fixes for vulnerabilities CVE-2021-46141 and CVE-2021-46142, as well as minor fixes related to the build system, compiler warnings and documentation. For more details please check the change log.
Last but not least: If you maintain uriparser packaging or a bundled version of uriparser somewhere, please update to 0.9.6 — thank you!
CVE-2013-0340 "Billion Laughs" fixed in Expat 2.4.0
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, precisely C99. It is cross-platform and licensed under the MIT license.
Expat 2.4.0
and follow-up release 2.4.1
have both been released earlier today.
Release 2.4.0 fixes long known security issue
CVE-2013-0340
by adding protection against so-called
Billion Laughs Attacks,
a form of denial of service against applications accepting XML input,
in all known variations,
including recent flavor Parameter Laughs.
I first became interested in detecting Billion Laughs Attacks back in 2008, 13 years ago, already in context of Expat at the time, but on top of it rather than from the inside, and long before I joined maintaining Expat in July 2016. In 2017 the topic got back on my radar, and by 2020 I eventually decided to make the topic a personal priority. In an e-mail conversation with Nick Wellnhofer in June 2020, Nick wrote:
I came to the conclusion that the most sensible check is to make sure that the total size of the output in bytes doesn't exceed the input size by a certain factor[.]
I was doubtful at first, digested it for multiple days, and then I was sure that he was right. Nick's conclusion became the foundation of my implementation for protection in Expat. That factor between input and output bytes is what the term "amplification" is about, that you will find used throughout the documentation.
Besides this security fix, there is the usual bunch of fixes and improvements in tooling, documentation, and the two build systems. For more details, please check out the change log.
If you maintain Expat packaging or a bundled copy of Expat or a pinned version of Expat somewhere, please update to 2.4.1. Thank you!
Sebastian Pipping
CVE-2021-3541 "Parameter Laughs" fixed in libxml2 2.9.11
In context of my work on protection against
Billion Laughs Attacks
for libexpat,
I played with the existing protection
of libxml2
against those attacks. As an unintended byproduct,
that led me to finding a bypass of that protection,
a new vulnerability in libxml2
prior to 2.9.11
that I call Parameter Laughs;
it has been assigned CVE number CVE-2021-3541 and is known as libxml2 issue 228 upstream.
Parameter Laughs is based upon well-known ideas from the Billion Laughs Attack — both use nested entities to amplify a small payload of a few hundred bytes up to gigabytes of content to process and hence wasting loads of RAM, CPU time, or both — but in contrast Parameter Laughs…
- uses parameter entities
(syntax
%entity;with%) rather than general entities (syntax&entity;with&) and - uses delayed interpretation
to effectively sneak use of parameter entities
into the so-called "internal subset" of the XML document
(the "here" in
<!DOCTYPE r [here]>) where undisguised parameter entities are not allowed, with regard to the XML specification.
What do I mean by "delayed interpretation"? Let us declare a parameter entity like this:
<!ENTITY % pe_2 "%pe_1;<!---->%pe_1;">
Now during replacement of reference %pe_2;
text % is turned into %
and hence %pe_1; becomes %pe_1;.
That triggers two new rounds of replacement
for %pe_1; after %pe_2; has been fully replaced —
there you have the delay (and the exponential growth).
Here is what Parameter Laughs looks like as a complete XML document (added 2021-05-25):
<?xml version="1.0"?> <!-- "Parameter Laughs", i.e. variant of Billion Laughs Attack using delayed interpretation of parameter entities Copyright (C) Sebastian Pipping <sebastian@pipping.org> --> <!DOCTYPE r [ <!ENTITY % pe_1 "<!---->"> <!ENTITY % pe_2 "%pe_1;<!---->%pe_1;"> <!ENTITY % pe_3 "%pe_2;<!---->%pe_2;"> %pe_3; <!-- not at full potential, increase towards "%pe40;" carefully --> ]> <r/>
Compared to something like arbitrary code execution, Parameter Laughs is "only" a denial of service attack. Its eager use of RAM made my machine need a hard reset in practice: maybe that's something that you want to be protected against, too.
(German) Fwd: Frag einen Obdachlosen: Dominik über kalte Nächte, Rastlosigkeit und Gewalt auf der Straße
Dieses Interview ist Teil der Serie Frag ein Klischee von hyperbole mit vielen anderen spannende Interviews.
Expat 2.3.0 has been released
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, precisely C99. It is cross-platform and licensed under the MIT license.
Expat 2.3.0 has been released earlier today. Simplified, this release brings…
- bugfixes,
- improvements to both build systems, and
- improvements to
xmlwfusability.
For more details, please check out the changelog.
With this release, the combination of continuous integration and Clang's sanitizers — in Expat's case AddressSanitizer ("ASan"), LeakSanitizer ("LeakSan") and UndefinedBehaviorSanitizer ("UBSan") — proved invaluable once more by preventing the introduction of new bugs into the code base. It was interesting to see in particular, how Clang 11 found an issue that Clang 9 was still blind to; so updating the toolchain paid off.
Let me take the occasion of one bugfix in 2.3.0 related to function
XML_ParseBuffer for a reminder that using
XML_ParseBuffer over XML_Parse can reduce your application's
memory footprint by up to a factor of 2, because you no longer
keep the the same data in two buffers — one outside of Expat and one inside.
With XML_ParseBuffer those two buffers become one.
I have taken the close releases of two C libraries —
first uriparser 0.9.5 about a week ago
and now libexpat 2.3.0 —
for a reason to research answers to my own open questions about bumping linker arguments -version-info C:R:A properly an every situation.
That led to finding a simpler, more human-friendly algorithm,
and also building a free interactive web-tool
served at https://verbump.de/ to make that topic more approachable to the community.
I still see many old, buggy, vulnerable copies of Expat on the Internet: anything unpatched before 2.2.8 is documented vulnerable, in particular. If you maintain Expat packaging or a bundled copy of Expat or a pinned version of Expat somewhere, please update to 2.3.0. Thank you!
Sebastian Pipping
uriparser 0.9.5 released
A few hours ago uriparser 0.9.5 has been released. Version 0.9.5 comes with improvements to the build system and one key bugfix that affects both resolution of URI references and normalization of URIs. For more details please check the change log.
Last but not least: If you maintain uriparser packaging or a bundled version of uriparser somewhere, please update to 0.9.5 — thank you!
Never Mis-Bump an .so Version Again
TL;DR — I built a free interactive web-tool and also found an alternative, more human-friendly algorithm.
For every software release that involves a shared library
you have to consider bumping the -version-info C:R:A part of your linker arguments
so that your libxyz.so.1.2.3 numbers match the semantic changes you did since the previous release.
Finding the correct new set of numbers can be a bit tricky. The current best place for how to bump them properly is probably section 7.3 Updating library version information of the GNU Libtool documentation. Ignoring the details, you'll be given this very structure:
- Start with version information of ‘0:0:0’ for each Libtool library.
- [..]
- If [..].
- If [..].
- If [..].
- If [..].
It took me a while to figure out what I'd need to do when multiple of those ifs apply: what they give you is an algorithm to follow step by step — it involves state and that state is carried from one step to the next.
While that algorithm is precise, it is a lot better suited to machines than humans. One reason is that — with multiple steps and state involved — there is quite some chance for the result to turn out wrong. Does it have to be that complicated?
In this post I would like to offer two things:
-
A simpler algorithm that doesn't involve state or pen and paper.
-
A web-tool to play with things interactively.
A Stateless Algorithm
So let's get rid of the overlapping ifs and state and move
to exclusive else if instead.
The stateless algorithm is this:
-
If it's the first release ever go with
-version-info 0:0:0. -
Else if you haven't made any changes to the source code but still need to do a re-release,
keep the version info untouched and re-use the same values. -
Else if you have made backwards-incompatible changes to the API — removed or changed something existing — bump applying
+1/=0/=0:-version-info C:R:Abecomes-version-info <C+1>:0:0. -
Else if you have only added to the public API and are sure of backwards compatibility bump applying
+1/=0/+1:-version-info C:R:Abecomes-version-info <C+1>:0:<A+1>. -
Else bump applying
+0/+1/+0:-version-info C:R:Abecomes-version-info C:<R+1>:A.
The Interactive Web-Tool
The small interactive web-tool I built is now online at https://verbump.de/. If you like it, please support it by starring the GitHub repository. Thank you!
For a clickable preview:
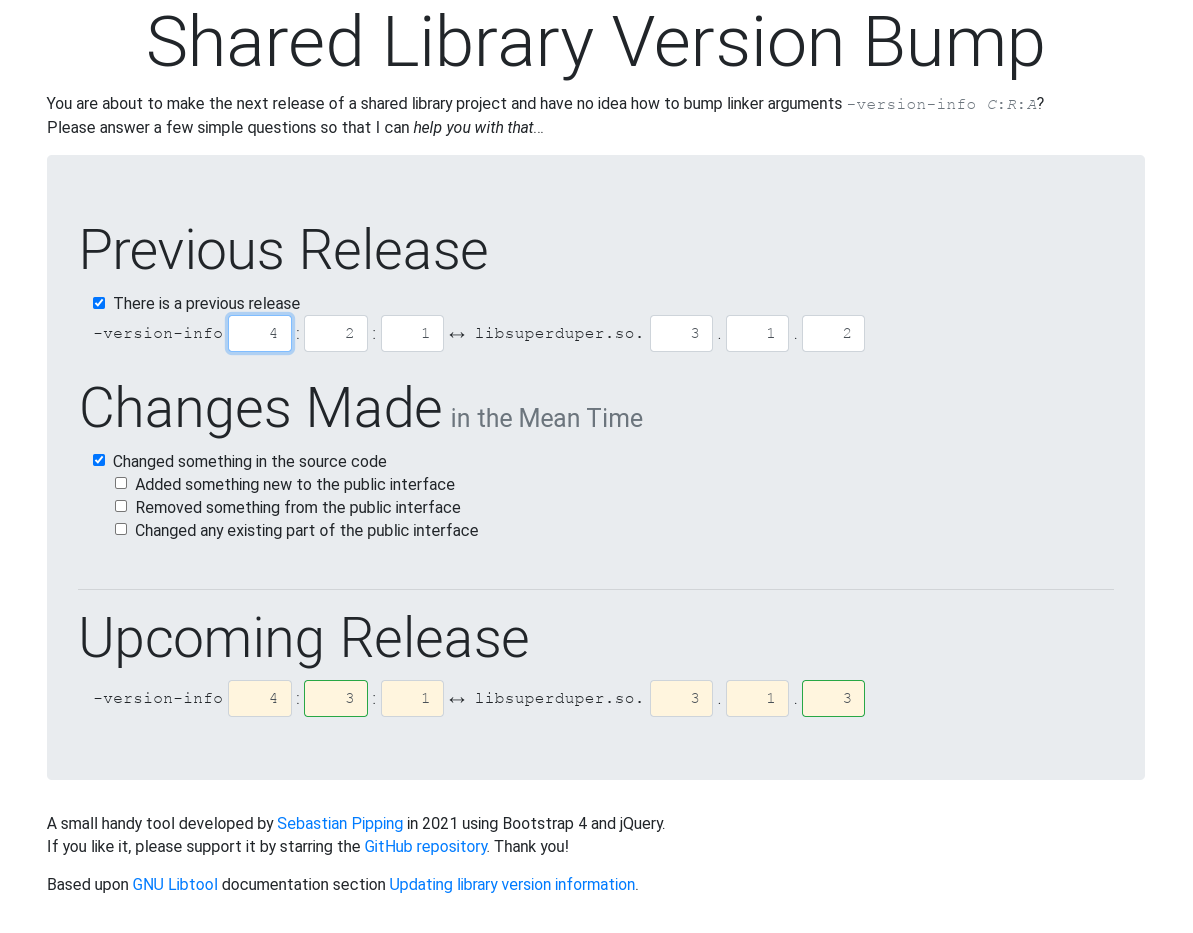
Enough version bumping for today.
The Purpose of Software Testing
In March 2019, someone's public statement about the purpose of automated software testing prompted me to reflect again on what I considered the true purpose of automated software testing, myself.
What if we took testing away?
For a moment, let's imagine a world without any automated software testing —
none at all.
Now, please ask yourself, without testing:
- Can we add new members to the team and have them find the things they broke by themselves?
- Can we change the software with low risk?
- Can we safely update third-party dependencies?
- Can we move fast without breaking things?
- Can we rest assured that the bugs we fixed yesterday will not return as regressions tomorrow?
What I would like to suggest is the following:
The point of software testing is this:
- to reduce risk and enable change,
- to retain development velocity over time, and
- to prevent damage to users and to the company.
Disagree? Drop me a mail at sebastian@pipping.org.
Replacing Ansible with salt-ssh
First, where am I coming from with Ansible?
There is this machine (or "box") that I used to manage using Ansible until recently. I wanted configuration management on that box so that if ever disk or VM or the entire hosting provider would go away, I would have a magic button to start a rebuild from nothing, grab a coffee, and have things work the same again. I wanted Ansible for that task because it's fairly easy and approachable, requires nothing but working SSH access from the host system, and is written in Python. Unlike Puppet, Chef, CFEngine and SaltStack — or so I thought.
Over time using Ansible I noticed that when I made changes to a playbook I was repeatedly facing the same challenge: Either I run the whole playbook and wait for many de-facto no-op tasks or I invest in annotation with tags, save some runtime but need to deal with the shortcomings that tags have in Ansible.
Tags in Ansible: What shortcomings?
Tags in Ansible have two problems that bug me.
First, you'll need to manually propagate the same tag to all dependency tasks,
especially those referenced in
when-conditionals
or else you'll run into undefined-variable issues
because the task due to register that variable has not been executed.
So that's something I would have to take good care of, manually.
Secondly, tags and loops do not work well together in Ansible. What I would like to do is use the iteration item as a tag like this:
- hosts: all tasks: - name: Add Docker users user: name: "{{ item }}" groups: docker append: yes loop: - ssl-reverse-proxy - example1-org - example2-net tags: # NOTE: Does not work! # Gets you: ERROR! 'item' is undefined - "{{ item }}"
Unfortunately, this gets me ERROR! 'item' is undefined because
tags do not support loops like that in Ansible.
I can address this problem by
- a) having two verbatim copies of that list,
- b) extracting and re-using a variable, or
- c) making use of YAML references.
A version using YAML references could look like this:
- hosts: all tasks: - name: Add Docker users user: name: "{{ item }}" groups: docker append: yes loop: &users - ssl-reverse-proxy - example1-org - example2-net tags: *users
More importantly though, I'll also need to be okay with the whole loop being run if I ask for any of those tags now, which means additional runtime for no value.
I didn't feel like I wanted to deal with these shortcomings of tags most of the time so instead I started to work on other tasks while the whole playbook was running, and got back to it when there were results.
It was hard to accept one other thing though: When I ran the playbook two times in a row, for the second run Ansible would take about 4 minutes to do nothing but confirming that all the work was already done. Why? Would I have to accept that it was that slow?
When Ansible is slow, how fast can I get it to be?
So I started looking for ways to improve Ansible speed, and SSH pipelining, disabling fact gathering, and Mitogen helped but wouldn't get runtime below 3 minutes, so I was not very happy. On a sidenote Mitogen doesn't support Ansible >=2.10 as of this writing so that boost in speed would come at the cost of being stuck with Ansible 2.9 in the past for longer, which is not ideal either.
So I accepted 3 minutes as the minimum runtime of that particular playbook at that time. And started wondering about looking elsewhere.
Can Salt be used like Ansible?
Maybe Salt had some way without all those minions, masters, daemons, agents that seemed like a given to me when I last had a few bits to do with SaltStack at a previous job a few years ago. To me delight, I did find salt-ssh this time. salt-ssh was introduced with the release of Salt 0.17.0 on 2013-09-26, it's not actually new.
So I was trying to answer the question:
Can I port my existing Ansible playbook to salt-ssh, will it be fun and work well, and will it be faster than 3 minutes for when it doesn't actually need to do anything?
A summary of my existing Ansible playbook
For some context, what is that playbook of mine doing anyway?
For an almost complete high-level summary (if you're interested):
- Configure sshd, an SSH pubkey, restart the service as needed
- Install Docker from a dedicated repository, having it running and enabled, install docker-compose
- Configured firewalld to be friends with Docker
- Create a specific Docker network for a Caddy-based SSL reverse proxy to talk to website containers
- Configures and activates dnf-automatic so that it updates packages by itself, restarts outdated services and reboots the VM when tracer detects need to
- Adjusts systemd-resolved config to no longer expose LLMNR port 5355 to the world without need to
- Closes port 9000 to the world previously exposed by the cockpit service
- Makes sure that
${HOME}/.local/binis in$PATHfor all users - Downgrade cgroup to v1 for Docker by adjusting the kernel command line and re-creating the GRUB config for the change to have actual effect
- Install some tools for manual inspections, e.g.
htop,tmuxandncdu - Create some bare Git repositories to host off-GitHub website content
- Clone some Git repositories containing docker-compose website projects and keep them up to date with upstream
- Spin up multiple docker-compose based service and have them do rebuilds and restarts whenever their underlying Git clone changed
- Set machine hostname
It's not very different from this playbook actually, just a bit bigger.
First steps and pains with salt-ssh
I started making my way through the official
Agentless Salt: Get Started Tutorial
and got stuck rather quickly.
I wanted execution as an unprivileged user but
despite obeying the tutorial in detail
I ran into errors about not being able to write to /var/cache/ — for good reasons — like these:
# salt-ssh '*' test.ping [ERROR ] Unable to render roster file: Traceback (most recent call last): [..] PermissionError: [Errno 13] Permission denied: '/var/cache/salt/master/roots/mtime_map'
And while the docs used absolute paths like /home/vagrant/salt-ssh/ everywhere,
I wanted relative paths that would work with a Git repository cloned anywhere in the file system hierarchy.
Not to mention that
log_file needs to be ssh_log_file
in the tutorial.
So with all of that figured out after a while, this minimal setup satisfied all of my needs:
execution as an unprivileged user,
relative paths with the help of root_dir: .,
significantly less noisy output through state_output_diff: True,
and a place to start adding playbook-like things to. For a bird's eye view:
# tree . ├── master ├── pillar │ ├── data.sls │ └── top.sls ├── roster ├── salt │ └── setup.sls └── Saltfile
In more detail, looking into these files:
File Saltfile:
salt-ssh: roster_file: ./roster config_dir: . ssh_log_file: ./log.txt
File master:
root_dir: . cachedir: ./cachedir file_roots: base: - ./salt pillar_roots: base: - ./pillar state_output_diff: True
File roster:
host1: host: host1.tld user: root host2: host: host2.tld user: root
File pillar/top.sls:
base: '*': - data
With that as a base I can now port the playbook over in a new file salt/setup.sls.
For example, let's adjust the Open SSH server config
to know my public key (that I'll store at salt/ssh/files/authorized-keys-root.txt),
to disable password-based log-in (to protect against brute-force log-in attempts)
and be sure that the server makes use of the adjusted configuration:
ssh-daemon: # Set SSH public keys for root ssh_auth.present: - user: root - source: salt://ssh/files/authorized-keys-root.txt # Disable password-based log-ins to SSH file.keyvalue: - name: /etc/ssh/sshd_config - key: PasswordAuthentication - value: "no" - separator: " " - uncomment: "#" - require: - ssh_auth: ssh-daemon # Restart sshd service to apply changes in configuration service.running: - name: sshd - reload: True - watch: - file: ssh-daemon
That state file was made with Fedora 32 in mind, by the way.
With that local setup we can now run commands like:
# salt-ssh '*' test.ping # salt-ssh '*' grains.items # salt-ssh '*' state.apply setup test=True # salt-ssh '*' state.apply setup
It took me maybe one and a half day to port the whole playbook to salt-ssh and be confident with the result. What did it get me?
- (What I first believed to be a) significant reduction of runtime: Down from 3-4 minutes with Ansible to about 1 minute with salt-ssh… but I'll get to why these numbers are misleading, below
- A high-level language leveraging YAML with idempotency in mind, just like with Ansible
- Being able to stay agentless: No minions, no masters, just SSH
- More flexibility (but also some duty) with regard to state dependencies and order of execution
- Being able to use Jinja templating right in the playbook (or "Salt state file") unlike with Ansible
- Experience with a new tool to add to my DevOps toolbox
Only after porting to SaltStack it became clear
that some badly-written parts of the original Ansible playbook were a big contributing factor
to its excessive runtime.
For instance, the playbook was using module package with a loop…
- hosts: all tasks: - name: Install distro packages package: name: "{{ item }}" state: present loop: # NOTE: Bad idea, very slow - git - htop - ncdu
…rather than a list of names:
- hosts: all tasks: - name: Install distro packages package: name: # NOTE: Better, a lot faster - git - htop - ncdu state: present
With as many as 20 packages to check for, this single loop alone contributed heavily to the initial 4 minutes runtime with Ansible for when there was not actually anything left to do.
In a fair comparison with a well-written playbook, Ansible and salt-ssh exhibit close to identical runtime for me now.
Still, after having used both Ansible and SaltStack I think it's fair to say that I consider myself a salt-ssh convert by now.
I do hope that SaltStack gets better at fixing bugs in the future. All the hiccups and limitations I ran into with version 3001.1 were related to features that I'd consider mainstream enough that I shouldn't even have seen them, given the size of the community.
Things I ran into include:
- #29142 — Limitation: Same function twice per state
- #35592 — Limitation: Allow multiple when function is different
- #49273 — Bug: Parallelization is sequential with requisites
- #53664 — Bug: getstarted/ssh/connect.html is incomplete
- #57778 — Bug: pkgrepo.managed always reported as "changed"
- #54449 — Bug: Issues with installing python3-docker
I hope those are not a sign of structural issues with SaltStack. VMWare bought SaltStack in September 2020 so I'm hoping that it turns out for the best. I'm happy to help out with pull requests once I'm convinced that I won't be wasting my time.
For more about using salt-ssh to replace Ansible, maybe Duncan Mac-Vicar P.'s article "Using Salt like Ansible" is of interest to you.
That's enough Salt for me today. Did I miss anything? Please let me know.
Best, Sebastian
Expat 2.2.10 has been released
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, precisely C99. It is cross-platform and licensed under the MIT license.
Expat 2.2.10
has been released earlier today. This release
fixes undefined behavior from pointer arithmetic with NULL pointers,
fixes reads to uninitialized variables
uncovered by Cppcheck 2.0,
adds documentation on exit codes to the man page of command-line tool xmlwf,
brings a pile of improvements to Expat's CMake build system,
and more.
For details, please
check out the changelog.
If you maintain Expat packaging or a bundled copy of Expat or a pinned version of Expat somewhere, please update to 2.2.10. Thank you!
Sebastian Pipping