Expat 2.8.2 released, fixes 13 vulnerabilities
For readers new to Expat:
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, specifically C99. It is cross-platform and licensed under the MIT license.
Expat 2.8.2 was released today. The key motivation for cutting a release and doing so now was getting security and non-security bugfixes out to users. On the security side, 13 vulnerabilities have been fixed:
- CVE-2026-50219 — missing control flow integrity checks
- CVE-2026-56131 — missing control flow integrity checks
- CVE-2026-56132 — out-of-bounds write
- CVE-2026-56403 — integer overflow
- CVE-2026-56404 — integer overflow
- CVE-2026-56405 — integer overflow
- CVE-2026-56406 — integer overflow
- CVE-2026-56407 — integer overflow
- CVE-2026-56408 — integer overflow
- CVE-2026-56409 — integer overflow
- CVE-2026-56410 — integer overflow
- CVE-2026-56411 — integer overflow
- CVE-2026-56412 — missing control flow integrity checks
The missing control flow integrity checks were brought to light by Steve Stagg in CPython, by Yousef Shanableh, Asher Darden, Haris Hussain, Sajin S of Astra Security and fixed by Kartik Kenchi, Haris Hussain and me.
The out-of-bounds write was reported and fixed by Alessandro Gario of Trail of Bits, Anthropic and Matthew Fernandez.
The integer overflows were reported and fixed by Kartik Kenchi and me.
Thanks to everyone who contributed to this release of Expat!
It it worth reminding that:
- Following the curl project, the libexpat project is on "security vacation" now until 2026-08-01, i.e. new vulnerability reports will not be accepted until then.
- CVSS scores are unreliable and not a metric to base decisions on.
For more details about this release, please check out the change log.
If you maintain Expat packaging, a bundled copy of Expat, or a pinned version of Expat, please update to version 2.8.2. Thank you!
Sebastian Pipping
Expat 2.8.1 released, CVE-2026-45186 and CVSS unreliability
For readers new to Expat:
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, specifically C99. It is cross-platform and licensed under the MIT license.
Expat 2.8.1 was released yesterday. The key motivation for cutting a release and doing so now was:
- Fixing vulnerability CVE-2026-45186 that allows easy denial of service.
The vulnerability was reported to me responsibly about eight months ago by Nick Wellnhofer, the long-time and past maintainer of libxml2.
The attack relies on Expat <2.8.1 using an
O(n²) runtime algorithm
— a for loop — to check for collisions among attribute names.
It takes nothing more than dialing up XML document…
<!DOCTYPE d [ <!ATTLIST e a0 CDATA "" a1 CDATA "" a2 CDATA ""> ]> <d/>
…from 3 attributes to a number big enough for the specific target of the attack.
It should be noted that a layer of compression around XML can significantly reduce the minimum attack payload size.
There is an attack payload generator available for download: please use it responsibly!
Berkay Eren Ürün and I teamed up
for a fix. It uses a hash table
instead of a linear loop to detect collisions,
which turns overall runtime from O(n*n) into O(n).
For some numbers (from older ThinkPad X220 hardware):
| Count | Runtime unfixed | Runtime fixed | Payload size |
|---|---|---|---|
| (seconds) | (seconds) | (uncompressed, bytes) | |
| 10,000 | 0.17 | 0.03 | 135,615 |
| 100,000 | 13.22 | 0.24 | 1,395,615 |
| 200,000 | 59.71 | 0.49 | 2,795,615 |
| 400,000 | 253.18 | 1.04 | 5,708,119 |
And a quick graph:
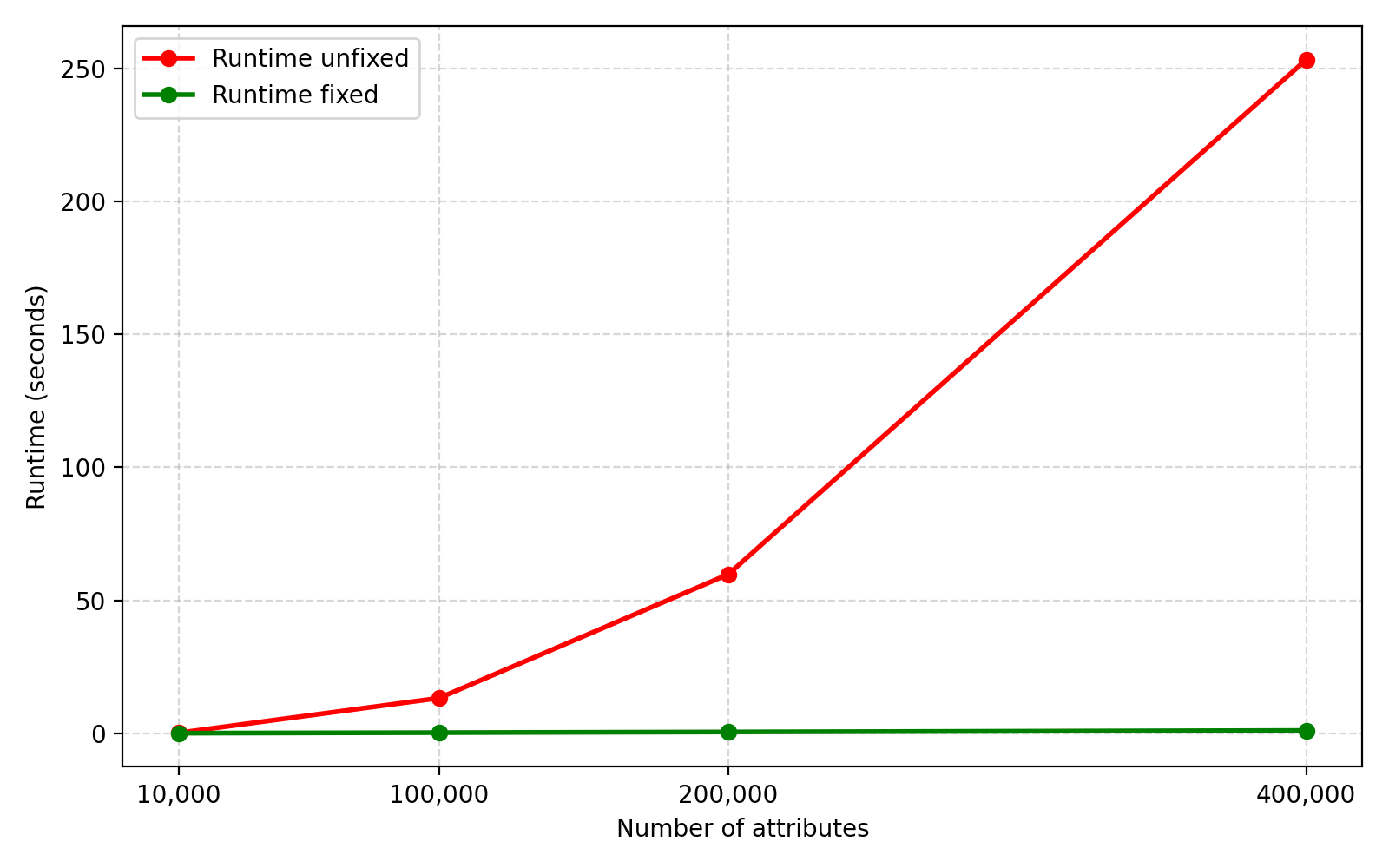
It is worth noting that after I filed a CVE request with Mitre,
someone turned my classification as remote (i.e. parsing from the wire)
to mistaken local (i.e. local account access needed) and also to
"Attack complexity: High" when it is a simple as shown above
and with an attack payload generator being public.
That results is an unrealistically low current
CVSS
score "2.9 of 10" on GitHub…

…and also in NVD. A more realastic score than 2.9 would be 5.3 to 7.5.
I have requested a fix from Mitre in the meantime, but that's not fixing the core issue. This could serve as both a concrete example and a reminder that:
-
CVSS scores are unreliable: they are often over- or (worse) underestimating risk.
-
CVSS scores (and CVE reports) are edited by individuals that may or may not know better than the reporting individuals and/or the maintainers upstream.
-
CVSS score is not a metric to base decisions about vulnerabilities on.
Thanks to everyone who contributed to this release of Expat!
For more details about this release, please check out the change log.
If you maintain Expat packaging, a bundled copy of Expat, or a pinned version of Expat, please update to version 2.8.1. Thank you!
Sebastian Pipping
Steven, please fix the 1% loss/gain graph!
Back in December 2023, I got curious about Steven Bartlett's then-new book The Diary of a CEO: The 33 laws of business and life and ordered a copy for myself. I dived right in. On page 184 this graph hit me:
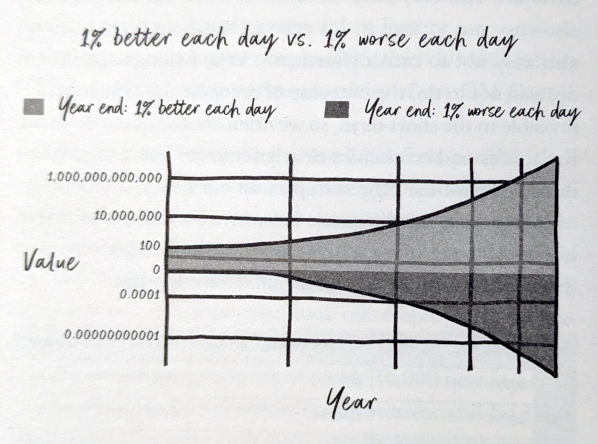
It is meant to be about how 100 USD develop over time with either constant 1% loss or 1% gain per day.
It puzzles and amazes me to this day how this graph — with all the things wrong about it, even for a schematic graph — made its way into a published book: It feels unreal. In particular:
-
The loss curve is "bending the wrong way": It is presented as concave when it should be convex.
-
The placement of 0 (zero) on the Y-axis is wild.
-
The graph has a log scale but seems to want to still live in the linear world.
Here is what that graph could have been with matplotlib (source code Gist in Python), either with a linear scale or with a truly logarithmic scale:
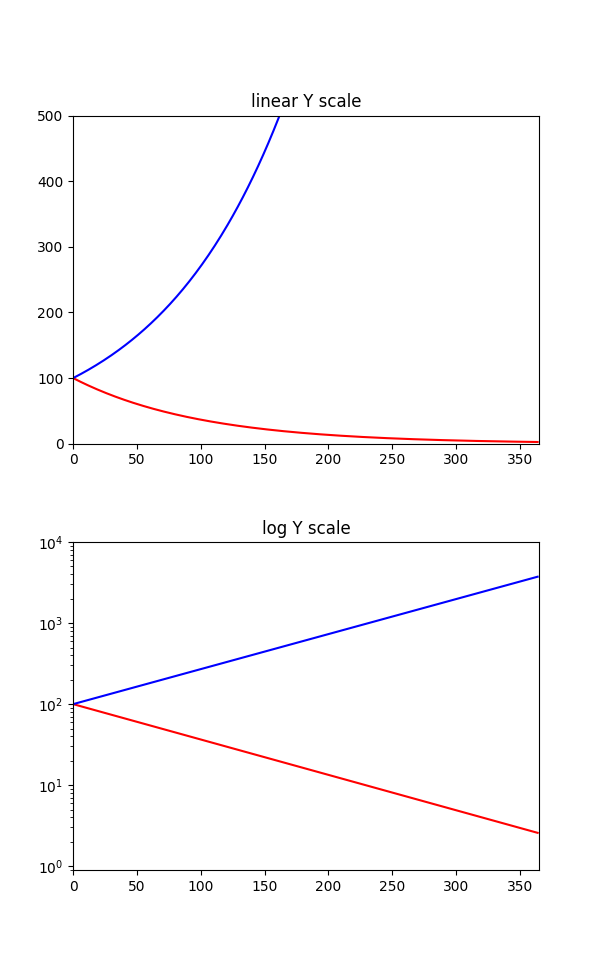
For comparision, here is how James Clear, the author of the book Atomic Habits, turns this into a working schematic graph for an article of his:
Steven, if you read this, please fix the 1% loss/gain graph for the next edition of the book — thank you!
-- Sebastian Pipping
Fwd: Karen Hao interview at DOAC
Expat 2.8.0 released, includes security fixes
For readers new to Expat:
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, specifically C99. It is cross-platform and licensed under the MIT license.
Expat 2.8.0 was released two days ago. The key motivation for cutting a release and doing so now was:
- Addressing security issue CVE-2026-41080 — insufficient entropy (CWE-331) —, and also
- Getting support for entropy extractor
getentropy(3)as well as bugfixes in the hands of users.
So, a summary "entropy and bugfixes" would be on point for the theme of this release.
What is entropy, and what does Expat need it for?
Entropy
(in computing) is the amount of information that an attacker does not know.
If your banking card pin has four decimal digits,
from 0000 to 9999, that's 10,000 possible combinations;
that's roughly 14 bits or less than two bytes
of entropy — import math; math.ceil(math.log2(10_000) / 8) in Python —
that the attacker is missing.
Expat needs high-quality entropy for a salt with its internal hash tables. Without an unknown-to-the-attacker hash salt, a hash table can be attacked using hash flooding, allowing denial of service attacks through crafted XML documents.
Now Expat 2.8.0 uses more entropy than past releases
— 16 bytes rather than previously 4 to 8 bytes (depending on architecture) —,
starts supporting entropy provider getentropy(3)
in the many systems that offer it
(including WASI, that lacks all other previously supported providers like
getrandom or
arc4random),
and also offers a new API function
XML_SetHashSalt16Bytes
that overcomes the limitations of its predecessor
XML_SetHashSalt.
For implementing the new cross-platform
getentropy(3)
support, I teamed up with Jérôme Duval.
The bug fixes were contributed by Matthew Fernandez:
the maintainer of Graphviz.
Thanks to everyone who contributed to this release of Expat!
For more details about this release, please check out the change log.
If you maintain Expat packaging, a bundled copy of Expat, or a pinned version of Expat, please update to version 2.8.0. Thank you!
Sebastian Pipping
Expat 2.7.5 released, includes security fixes
For readers new to Expat:
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, specifically C99. It is cross-platform and licensed under the MIT license.
Expat 2.7.5 was released earlier today. The key motivation for cutting a release and doing so now is three security fixes:
-
CVE-2026-32776
—
NULLpointer dereference (CWE-476) - CVE-2026-32777 — infinite loop (CWE-835)
-
CVE-2026-32778
—
NULLpointer dereference (CWE-476)
The first NULL pointer dereference was reported and fixed by
Francesco Bertolaccini
of Trail of Bits with help from their AI tool
Buttercup.
The infinite loop
denial of service
issue was uncovered by
Google ClusterFuzz through
continuesly fuzzing with xml_lpm_fuzzer
that Mark Brand of Project Zero
and I teamed up on in the past for Expat 2.7.0.
Berkay Eren Ürün and I teamed up
for analysis and a fix under a 90 day disclosure deadline.
The second NULL pointer dereference was reported by
Christian Ng, and he and I teamed up on a fix.
So much for the fixed vulnerabilities. There are also three known unfixed security issues remaining in libexpat, and there is a GitHub issue listing known unfixed security issues in libexpat for anyone interested.
Thanks to everyone who contributed to this release of Expat!
For more details about this release, please check out the change log.
If you maintain Expat packaging, a bundled copy of Expat, or a pinned version of Expat, please update to version 2.7.5. Thank you!
Sebastian Pipping
Learn from me!
Not too long ago, someone literally asked me what they "could learn from me", and that question has stuck with me since.
One thing it made me do was label about 30 earlier blog posts in a new blog topic "Learn from me" that contains posts I consider to be teaching something, be at least somewhat timeless, and be somewhat unique to this blog of mine — posts like:
Maybe more importantly though, there are some non-IT learnings that I would like to share with you now for a draft answer to that question "What can you (potentially) learn from me?" below:
-
Sometimes "throwing 50 bucks at it" is a good solution to a problem if you can.
Especially when you experienced poverty or near-poverty and were lucky to grew out of it later, there can be learned resistance to spend (reasonable) amounts of money to solve a problem. When you have an okay salary, spending ten hours on a problem, that does not give you joy and could be solved by spending (or giving up on gaining) 50 bucks can be worth reconsideration. (There is one particular person that learned this from me.) -
Pay attention to what people did not say.
Sometimes people use particular wording or omit things where a closer look reveals that their omission, them not saying it differently, reveals a hidden truth that they did not intend to share. Ask yourself: Why did they say it this way? What is that difference saying? What are they not saying? -
Meaning depends on the right level of zoom.
What do I mean? Activities like watering a plant can have meaning if your zoom level is a garden or the humans around that plant every day. If you zoom out too far or even up to universe level, the plant and these humans become a bunch of cells that lack any meaning. Zooming out to far destroys meaning and zooming in allows finding or creating meaning. Be mindful of the right zoom level. -
You can be one in a hundred and still not be wrong.
Just because everyone else says something is true does not make it true. Just because it's written in a book or told by a professor does not make it true. Trust in that possibility that you could be right. (From personal experience.) -
Be kind to service personnel.
It takes five positive things to outweigh one negative, and then… who is making up for the bad-day customers before you? Authentically be that someone if you can, pay it forward. -
The word "must" is hardly ever true.
When someone says they "must" do something, it's almost always they "want" or decide to do it but are afraid to take responsibility. Pay attention to use of the word "must" (and its siblings "have to", "must not" and "cannot") and try to be true about what you "must" or "want" to do. (Learned from Marshall B. Rosenberg.)
If you learned something here or would like to share your own answer, please find me at sebastian@pipping.org.
I will likely edit this post over time. Please be invited to bookmark it and return later 👋
Best, Sebastian
Expat 2.7.4 released, includes security fixes
For readers new to Expat:
libexpat is a fast streaming XML parser. Alongside libxml2, Expat is one of the most widely used software libre XML parsers written in C, specifically C99. It is cross-platform and licensed under the MIT license.
Expat 2.7.4 was released earlier today. The key motivation for cutting a release and doing so now is two security fixes:
-
CVE-2026-24515
—
NULLpointer dereference (CWE-476) - CVE-2026-25210 — integer overflow (CWE-190)
The NULL pointer dereference finding and fix were contributed by
Artiphishell Inc., and originated in AI.
Another highlight in this release is the introduction of (off-by-default)
symbol versioning
which Gordon Messmer
of Fedora
and I teamed up for. If you have seen things like @@GLIBC_2.42 before,
it's that same kind of symbol versioning.
The rest of the release consists of a mix of minor improvements and fixes,
particularly to
both build systems,
documentation, and
infrastructure.
Thanks to everyone who contributed to this release of Expat!
For more details about this release, please check out the change log.
If you maintain Expat packaging, a bundled copy of Expat, or a pinned version of Expat, please update to version 2.7.4. Thank you!
Sebastian Pipping
Fwd: The "60 Minutes" segment about the CECOT prison that was pulled last minute
When I tried watching The 60 Minutes Story The Trump Administration Doesn't Want You To See from my bookmarks today, I got error…
Video unavailable
This video is no longer available due to a copyright claim by Paramount Global companies[.]
…and so below you can find a re-upload if you also are curious what the pulled video is about:
Original title: The 60 Minutes story the Trump regime did not want you to see
For additional context:
Original title: Chris Murphy: Trump Has Taken 'Editorial Control Of CBS' After 60 Minutes Pulls Critical Segment
Fwd: In memory of GM Daniel "Danya" Naroditsky
Wikipedia: Daniel Naroditsky
Original title: In memory of Daniel Naroditsky ❤️
Original title: David Howell on his friend Daniel Naroditsky passing away
Original title: Justice for Grandmaster Daniel Naroditsky.